Quick Navigation:
- 1. How Duplicate Files Are Generated in Your Linux System
- 2. Why Should You Remove Duplicate Files on Linux
- 3. How to Find and Clean Linux Duplicate Files (3 Effective Methods!)
- 4. Additional Guide: Identify and Remove Duplicate Files with Easy Steps (Manually or automatically?)
We have a habit of downloading various files or content from the web. Additionally, we continually transfer files on our computers. As a result, we would have numerous duplicate files in our system without realizing it. It is common to find the same file on your storage drive in different directories or to back up some files in multiple locations, or you may have duplicate files with different names but the same content.
Duplicate files are mostly a waste of storage space. They occupy a considerable amount of storage and can lead to a shortfall in system storage. Therefore, it is essential to locate and prevent duplicate files from consuming too much space. This article will guide you through the best ways to find duplicate files and remove them.
![find duplicate files in linux]()
How Duplicate Files Are Generated in Your Linux System
Duplicate files are identical copies of original files stored or installed on your Linux system. Various reasons can lead to these files appearing on your system legitimately. There are many kinds of duplicate files containing documents, audio, video, images, and executable files. Too many redundant files in a Linux system can hurt its overall performance.
You may experience several issues on Linux caused by duplicate files. Having duplicate files can significantly increase the load on Linux. As a result, performance and functionality may suffer due to cluttered files.
The following are some ways in which duplicate files can appear on your Linux:
- Multiple downloads of the same file without being aware of it leave plenty of room for duplicate files to form.
- When transferring files between Linux and Windows, it is possible to import the same file more than once, resulting in duplication of files.
- Having backups of a specific file in various locations can also generate multiple copies.
![related articles]()
Quick Answer: How to Remove Duplicate Files Mac
If your MacBook is full of duplicate files, it can spoil your working experience. By occupying a large portion of your Mac's storage space, duplicate files can severely deteriorate its performance.
Why Should You Remove Duplicate Files on Linux
You need to ensure that any unwanted files are kept out of your Linux system for it to keep running smoothly. You can find and remove duplicate files safely on Linux using several methods. You can use these methods to keep your system up to date and clutter-free.
Besides improving Linux performance, removing duplicate files also frees up a lot of storage space by clearing countless unnecessary files. You get the following benefits by removing duplicate files on Linux:
- Allow Linux to operate effectively and efficiently without lagging issues.
- Free up a lot of storage space, which can be very useful.
- Systematically arrange files to avoid a hotchpotch of files.
- Optimize file sorting, reduce slowdowns, and speed up productivity.
How to Find and Clean Linux Duplicate Files
Finding and removing duplicate files becomes easy when you use the following methods:
- Method 1. Find Duplicate Files by Name
- Method 2. Find Duplicate Files by Size
- Method 3. Find Duplicate Files by MD5 Checksum
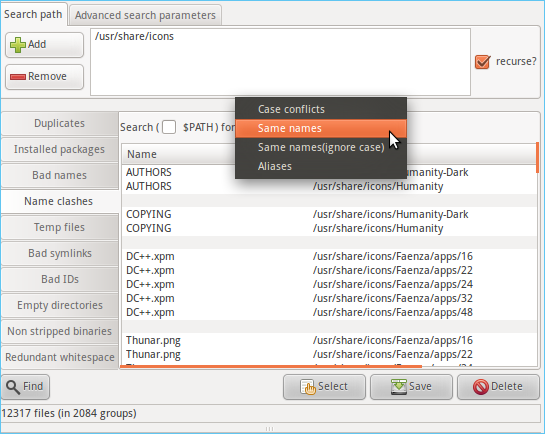
Method 1. Find Duplicate Files by Name
![find files by name in linux]()
If you don't want to use any duplicate finder, you find and remove all the duplicate files by searching their names. Using the following scripts, you can start the process:
Step 1. Just follow and write the script.
awk -F'/' '{
f = $NF
a[f] = f in a? a[f] RS $0 : $0
b[f]++ }
END{for(x in b)
if(b[x]>1)
printf "Duplicate Filename: %s\n%s\n",x,a[x] }' <(find . -type f)
Running this script will compare and show up all the files having the same names.
Note* This method is only applicable to find duplicate files having the same name. It does not compare the data they contain.
Step 2. Make sure the list shows all the files' names including the path like this.
Duplicate Filename: textfile1
./folder3/textfile1
./folder2/textfile1
./folder1/textfile1
Duplicate Filename: textfile2
./folder3/textfile2
./folder2/textfile2
./folder1/textfile2
Method 2. Find Duplicate Files by Size
![search duplicate files by size on Linux]()
This method is a quick way to find duplicates have the same size. Let's check how it works:
Note* This method is helpful for files having the same size as it does not analyze the content they have.
Step 1. Write the given script to find files with same size.
awk '{
size = $1
a[size]=size in a ? a[size] RS $2 : $2
b[size]++ }
END{for(x in b)
if(b[x]>1)
printf "Duplicate Files By Size: %d Bytes\n%s\n",x,a[x] }' <(find . -type f -exec du -b {} +)
Note* This method is helpful for files with similar size as it does not analyze the data they contain.
- The du command in the given script applies to calculate the file sizes.
- Find command takes a parameter called -exec du -b {} + to pass the file size to the AWK command.
Step 2. When you apply the given script, it will show the output like this:
Duplicate Files By Size: 20 Bytes
./folder3/textfile1
./folder2/textfile1
./folder1/textfile1
Duplicate Files By Size: 35 Bytes
./folder3/textfile2
./folder2/textfile2
./folder1/textfile2
Now, you can locate the file path to find and remove the duplicates.
Here are the details of the script so you can see what it does.
- <(find . – type f) - For AWK to read find's output, we must use process substitution.
- find . -type f - This command navigates all files in the searchPath directory.
- awk -F’/’ - We use ‘/’ as the internal variable of the AWK command. By doing so, you can extract the filename more easily. You will then find the filename in the last field.
- f = $NF - The variable f is used to save the filename.
- a[f] = f in a? a[f] RS $0: $0 - This code is useful if the filename doesn’t exist. We create access to map the original file path using this script code.
- b[f]++ - Another array b[] is created to track the number of files having the same name.
- END{for(x in b) - We are using this code to analyze all entries in the array b[]
- if(b[x]>1) - If there are several files with the same name as x, this means that there have been multiple copies of it.
- printf “Duplicate Filename: %s\n%s\n”,x,a[x] - At the end, this code use to print the duplicated filename x. To print all full paths including filename we use a[x].
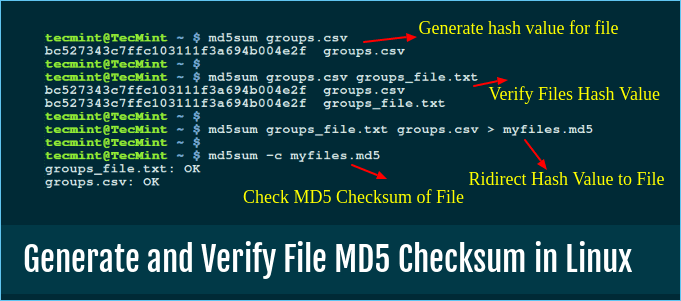
Method 3. Find Duplicate Files by MD5 Checksum
To identify duplicates using md5 checksum would be the most manageable solution for anyone. People use this function to locate files having the same checksum. Initially, the MDS checksum is designed to verify the integration of data.
![generate and verify file md5 checksum in linux]()
In addition, you can find files that probably have the same contents. To navigate an MD5 hash of a file, we can use the md5sum command in Linux.
Step 1. Let's begin by using the given script in the command shell:
awk '{
md5=$1
a[md5]=md5 in a ? a[md5] RS $2 : $2
b[md5]++ }
END{for(x in b)
if(b[x]>1)
printf "Duplicate Files (MD5:%s):\n%s\n",x,a[x] }' <(find . -type f -exec md5sum {} +)
- -exec md5sum {} + is the additon parameter to the find command.
Step 2. When you apply the given command, it will show the results as mentioned below:
Duplicate Files (MD5:1d65953b527afb4bd9bc0986fd0b9547):
./folder3/textfile1
./folder2/textfile1
./folder1/textfile1
In the result, you can see that we have three files that have the same name text-file-2, but the MD5 hash does not find them as their content is unique.
Additional Guide: Identify and Remove Duplicate Files with Easy Steps
People can encounter the hassle of duplicate files even if they are operating Linux or Windows. Although duplicate files are not tricky to get rid of, they can be annoying to find and delete. Let's discover the best method for you:
If you are a Windows user, you can also delete the avoided clutter of duplicate files.
Fix 1. Mannually Identify and Remove Duplicate Files
As we discussed in the case of Linux, you can also identify and remove duplicate files by sorting them by name or size. To find and delete duplicate files in Windows, you can open the folder from which you want to find duplicates. Now use the search feature in Windows Explorer, type the file extension and sort all the files by name or size. So you can identify all files with the same size or name.
Fix 2. Automatically Identify and Remove Duplicate Files
Finding and deleting copied files is a lengthy and troublesome process. We suggest you keep your hands on the best duplicate file finder that saves time and effort at the same time. Therefore, it is advisable to use EaseUS DupFiles Cleaner, which is famous for its advanced features and easy usability.
EaseUS DupFiles Cleaner is suitable for all internal and external storage drives, including USB drives and SD cards. Its advanced algorithm is ideal for finding all types of duplicate files with 100% accuracy.
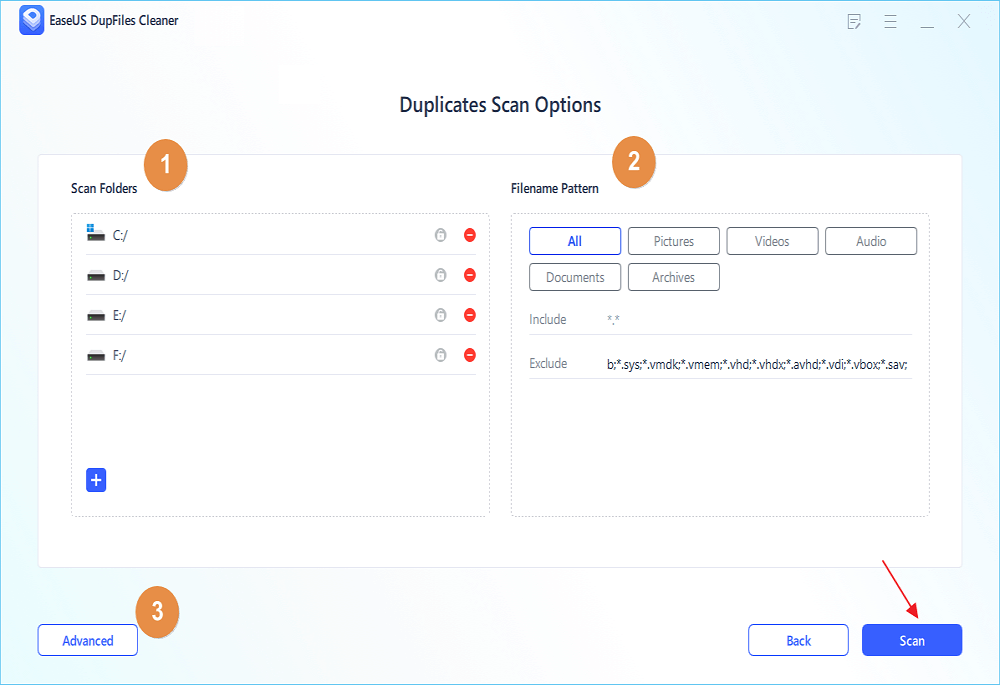
Here's how you can use this software to search and delete duplicate files on Winodows:
Step 1. Open EaseUS Dupfiles Cleaner and click Scan Now to start cleaning. EaseUS Dupfiles Cleaner will automatically select all data in all partitions. You can delete partitions you don't want to clean up by pressing the "-" sign in Scan Folders and choose the file types in Filename Pattern.
* You can click Advanced to customize the scan, and the system will turn on file protection mode by default.
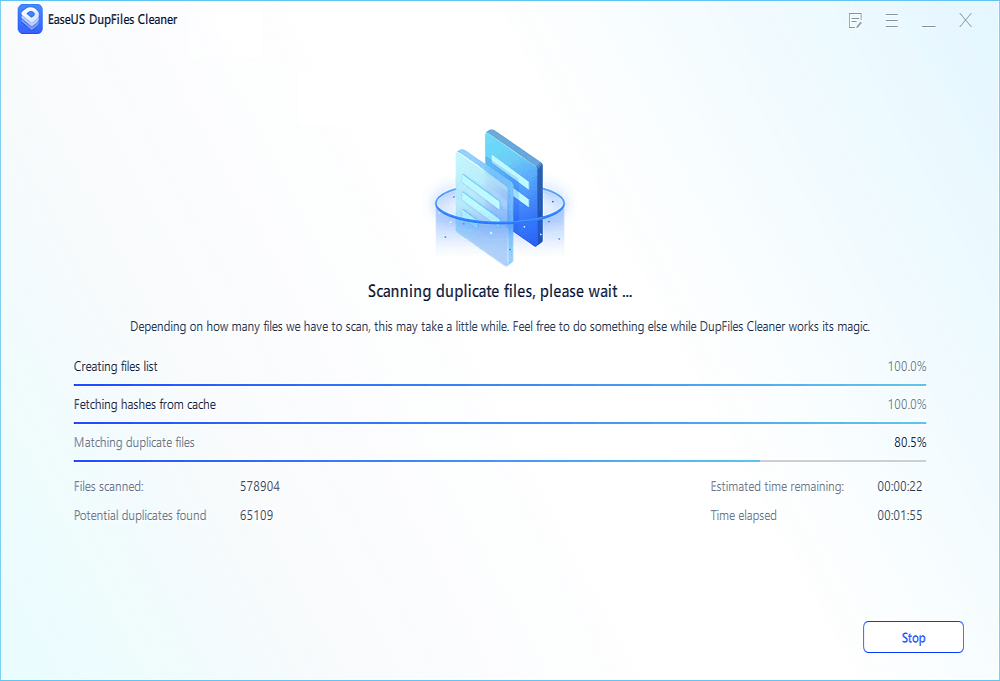
Step 2. The scanning process begins, please wait patiently. The time depends on how many files you have to scan.
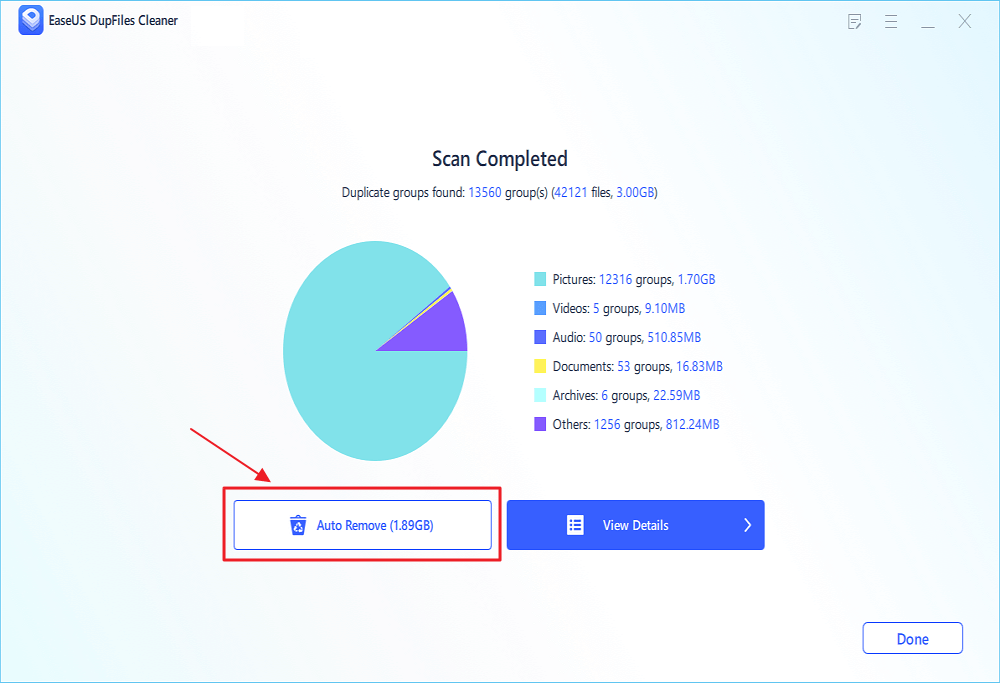
Step 3. After the scan is completed, you can click Auto Remove to achieve a one-click cleanup.
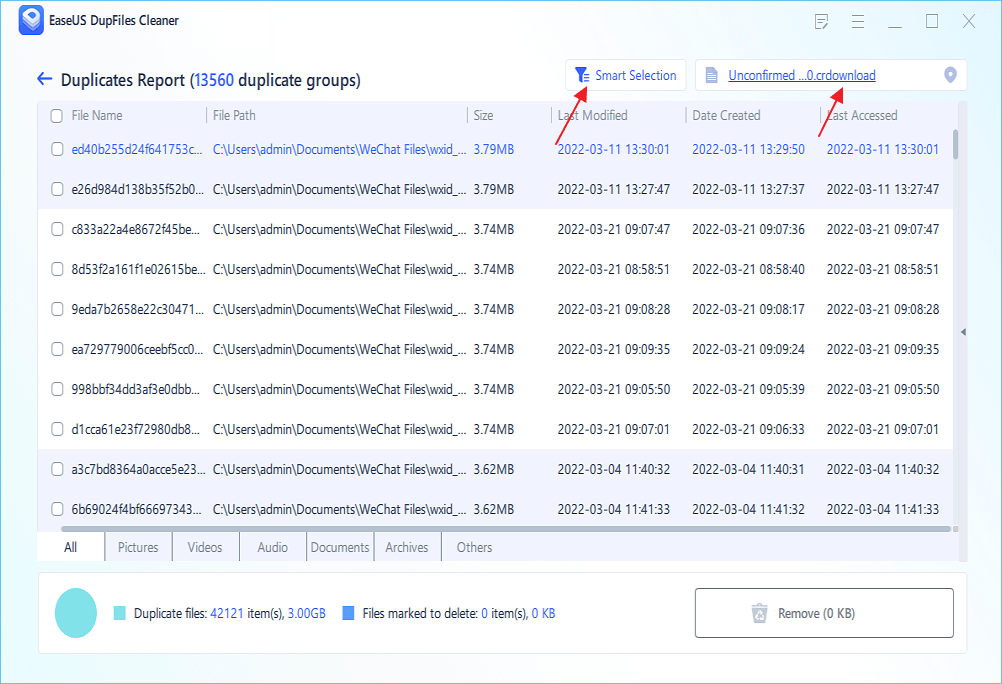
Step 4. If you still have some concerns, you can choose to click View Details to have a check.
* You can click Smart Selections to further check which type of files you need to clean up and if you cannot identify the content from the file name, you can directly click the file name in the upper right corner to preview it.